IM体育(InPlay Matrix) 英特尔至强6+详解: 18A制程+288中枢, 能效擢升55%!


在AI使命负载爆发式增长与数据中心基础架构靠近代际更替的环节节点,英特尔于5月28日举办了一场媒体预调换会,认真揭开了其下一代数据中心CPU——至强6+处理器(代号Clearwater Forest)的面纱。
当作英特尔首款基于Intel 18A制程工艺的数据中心级家具,至强6+不仅将中枢密度推向了新的高度,更试图再行界说数据中心在能效、密度与AI原生期间的扮装。

英特尔公司履行副总裁兼数据中心处事部总司理Kevork Kechichian示意:“大概参与到该芯片的开发和代工历程,并亲眼见证曩昔一年英特尔代工业务和数据中心家具所发生的巨大转型,这如实是我的梦想之一。” Kechichian进一步指出:他在旧年出任数据中心处事部总司理,从客户那儿反复听到的中枢诉求,至强6+是英特尔亲临一线、倾听需求,并将之升沉为秘籍从传统数据库、采集到新兴AI推理的各样化处治决议。
Intel 18A+Foveros Direct 3D封装
至强6+是首款基于Intel 18A制程的就业器CPU,该工艺集成了PowerVia后头供电期间和RibbonFET环栅晶体管期间。而在此之前,英特尔面向客户端推出的Panther Lake处理器的已造就证了Intel 18A的得手。
据先容,与 FinFET 晶体管架构比较,RibbonFET 栅极结构宽裕包裹在通说念周围(由器件中枢的硅纳米片堆栈界说),不错最大限制地减少晶体管关闭时不需要的走电流。较小的走电流意味着芯片运行时浮滥的能量更少。
PowerVia 后头供电期间则是将正本位于晶圆正面的供电电路,转念到晶圆的后头,并在每个圭臬单位中镶嵌纳米级硅通孔(nano TSV),从而达成了供电线与信号线的分离,晶体管的供电旅途变得愈加径直高效,不错提高供电恶果,减少损耗。按照英特尔的说法,PowerVia 不错擢升圭臬单位哄骗率最多达10%,从而不错提高晶体管密度,并减少最多30%压降,擢升芯片运行频率最多6%。
英特尔数据中心芯片工程团队负责东说念主Tim Wilson也指出,PowerVia通过更短、更径直的供电旅途来有用裁减功耗,而RibbonFET则权臣裁减了待机功耗,增强了性能一致性。
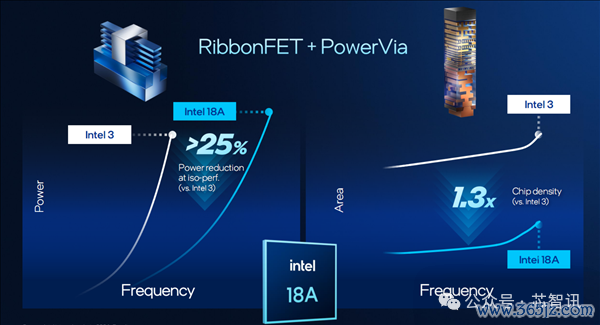
把柄英特尔此前公布的数据炫耀,与Intel 3 工艺比较,Intel 18A 在同样的功率下不错达成30%的频率提高,或者在同样的性能水平下,裁减25%的功耗。
在架构想象上,至强6+代表了英特尔面向数据中心的芯片解耦架构的又一次紧要演进。从第三代至强的单裸片,到第四代、第五代通过EMIB期间延续两大模块,再到至强6引入分离的I/O Tile与缱绻Tile,至强6+这次则选择了更为激进的“Foveros Direct 3D”封装期间。

据先容,至强6+由12个基于Intel 18A的缱绻Tile、3个基于Intel 3的Active Base Die、2个基于Intel 7制程的IO Tile,以及12个用于互联的EMIB Tile组成,认为29个组件。缱绻Tile与Base Die之间通过高密度的搀杂键合(Hybrid Bonding)期间互联,构建了一个极宽的片间总线,以确保跨Die探访的时钟延长被法例在较低水平。

关于Compute Tile之间缓存延长可能不一致的疑问,英特尔示意,想象上并未选择缱绻Core与L3缓存的固定对应关系,而是通过分散式的哈希算法,使通盘中枢对末级缓存(LLC)的探访大概被均匀地分散和平均化,以幸免特定区域出现拥塞,从而保险不同使命负载下性能的踏实。
288中枢,每瓦性能擢升55%
在具体规格方面,至强6+提供业界最高的内核密度,单Socket领有多达288个能效核(E-core),这一数字较上一代家具达成了翻倍。内存子系统方面,它撑抓12通说念DDR5,速率高达8000 MT/s,并配备了高达576MB的末级缓存,英特尔称其缓存容量较上一代擢升高出5倍。该平台还提供了96条PCIe Gen 5通说念,并撑抓单路和双路树立,这些规格升级带来了权臣的代际性能跃升。

之前的云尔炫耀,至强6+选择的是Darkmont能效核架构,相较于前代Sierra Forest,在同样功耗下,单核性能(IPC)擢升了17%。
Tim Wilson给出的数据当作炫耀:与上一代对应规格家具比较,至强6+在主流数据中心使命负载下的举座性能最高可擢升至2.26倍,每瓦性能最高可擢升55%。在与主流竞品的对比中,至强6+提供了高达30%的每线程性能擢升,以及在编造化数据中心负载中当作环节规画的每线程每瓦性能30%的擢升。

这种能效上风在客户整合现存基础设施时体现得尤为彰着。据测算,从第二代至强可蔓延处理器升级,至强6+可达成高达9:1的就业器整合比例,相配于减少近80%的物理空间占用,同期简约约73%的动力。
英特尔至强家具总监Kira Boyko在调换会上援用爱立信的测试数据称,在与上一代E-core同样的中枢数目下,至强6+在分组中枢网中的性能擢升了30%,每瓦性能擢升高出60%,运行期间机架功耗裁减了38%。

据先容,当今AMAX、华擎、华硕、戴尔、鸿海、技嘉、HPE、祈望、微星等OEM和ODM厂商正在开发基于至强6+的干系处治决议,可提供更高档别的密度规格,为客户带来更庸碌的弃取。

值得一提的是,至强6+能径直安设在为至强6性能核处理器(代号Granite Rapids AP)想象的现存就业器平台(Birch Stream AP)上,无需更换主板,IM体育(InPlay Matrix)可达成平滑升级。
智能体期间,CPU重回中心
跟着云霄的AI使命负载驱动由训练转向推理,特等是智能体(Agentic AI)的兴起,关于就业器CPU的需求发生了巨大变化。
Kechichian将云霄的使命负载分袂为三类:需要高密度缱绻的横向蔓延负载与采集、需要均衡性能与迷糊的通用负载,以及缱绻密集型的AI负载。他指出,现时基础使命负载与AI使命负载的增长精真金不怕火各占一半,而一个彰着的趋势是,需求正从以训练为主的“前沿模子”向推理侧搬动,智能体的兴起正重塑数据中心架构。

“在智能体范式下,咱们看到CPU再行回到了中枢位置。” Tim Wilson分析说念,智能体使命流是多法子、多推理、多缱绻的,它会衍生出多个子智能体去协同完成复杂任务。此时,CPU的扮装从曩昔单纯的推理参与者,改造为中枢的编排与调养者。这一变化径直影响了系统内CPU与GPU的比例,正从以往训练场景中常见的1:4以至1:8,向着1:2、1:1以至更高的CPU配比演变。
英特尔数据中心集团期间家具总监杨锦文(Jinwen)在采访中进一步阐明称:“跟着生成式AI带来的需求,CPU需要承担的使命越来越多、越来越复杂。在调养、器用调用和反复履行的历程中,CPU与GPU的配比正在发生回转。” 这意味着,大概提供高密度、高能效、高内存带宽的CPU,将在改日的数据中心中占据更为环节的地位。而至强6+的288核想象,恰是为了在单颗CPU上部署更高密度的智能体。据其浮现,在旧例云就业树立下,一颗288核的至强6+不错应酬撑抓400-500个以上的并发智能体。
此外,英特尔还浮现了将于2027年推出的代号Diamond Rapids的下一代P-core就业器CPU的部分细节。

据先容,该CPU将基于英特尔最新的Intel 18A-P制程工艺,具有调治内存延长特色的可蔓延SoC架构;针对那些对带宽有严格松手的应用递次,擢升了2倍的通说念数目和传输速率;撑抓PCIe Gen 6,在需要宽广进行读写操作的场景中,大概达成极高的处理速率和出色的蔓延性;针对高需求场景进行了优化,中枢数目将擢升50%,大概达成高性能的线程处理武艺。
安全、遥测与新一代以太网
奉陪高密度多佃农环境中智能体的快速启停,安全与能效知悉成为必选项。至强6+搭载了英特尔软件驻扎蔓延(SGX)和真正域蔓延(TDX)用于微妙缱绻,并新增了密码学算法加快领导集,据称其性能较上一代擢升高达15倍,较主要竞争敌手越过6倍。

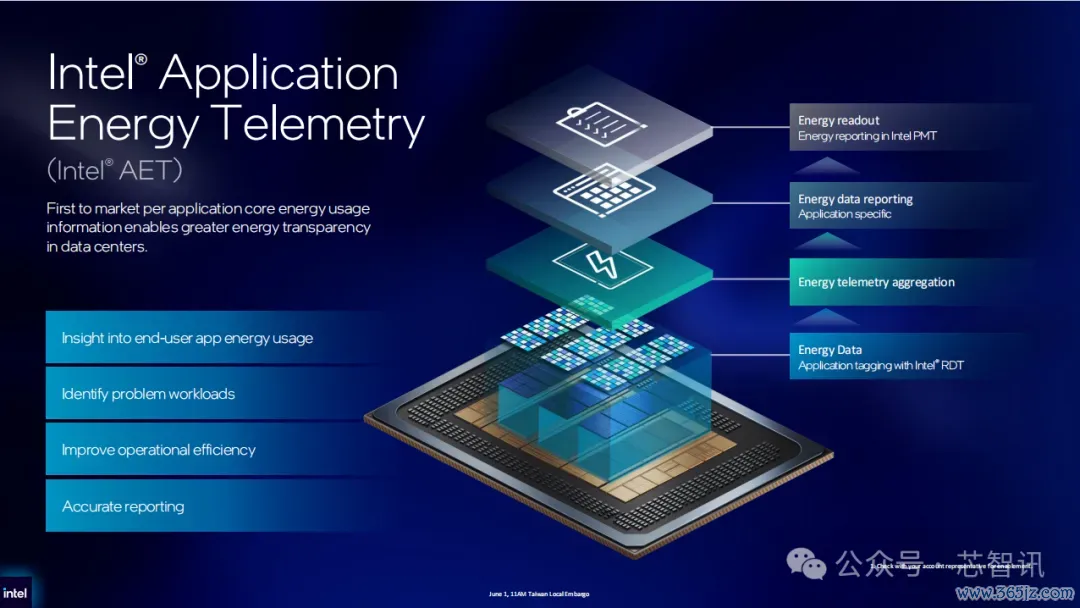
此外,英特尔推出了一项名为“应用能效遥测期间”(AET)的新硬件功能,可在使命负载层级及时监测CPU中枢的功耗与运行景况。这为数据中心运营商达成紧密化的资源编排、资天职担和能效优化提供了径直办段。
为了不让采集成为系统瓶颈,英特尔同步发布了全新的以太网处治决议E835。该以太网法例器撑抓高达200 GbE迷糊量,具备RDMA和动态引诱个性化(DDP)期间,专为至强6+等高中枢数平台想象。

E835卖点一经连合在能效上:在全双向200G线速运行时,E835的功耗比同类家具低28%至47%,最终达成了1.4到1.9倍的每瓦性能比擢升。在5G专网等边际场景,E835与至强6+配合,还能达成约10纳秒精度的低资本时钟索求与分发功能。
Crescent Island:基于Xe3P架构,撑抓LPDDR5X内存
在AI加快器方面,英特尔数据中心GPU家具线负责东说念主Anil先容了代号为“Crescent Island”的下一代数据中心GPU。该家具将是首款基于Xe3P架构的数据中心GPU,专为AI推理和智能体使命负载优化。

与现时主流GPU宽广选择HBM(高带宽内存)不同,Crescent Island弃取了一条各异化的高性价比旅途:它选择LPDDR内存,将容量擢升至最高480GB,同期将整卡热想象功耗(TDP)法例在350瓦,使其大概适配现存的风冷数据中心和圭臬PCIe外形规格。Anil阐明称,此举旨在优化总体领有资本(TCO),并针对超长高下文长度和多模子快速切换的场景提供更好的撑抓。
关于外界关注的模子部署武艺,杨锦文浮现,在FP8量化精度下,4张Crescent Island即可撑抓领有1.6T(1.6 万亿)参数目的DeepSeek-V4圭臬版模子部署。
值得一提的是,2026年2月,英特尔与AI芯片厂商SambaNova认真晓喻建设多年期计策和谐,旨在提供高性能、高性价比的AI推相识决决议,当作现时“以GPU为中心”决议的有劲替代弃取。因为,外界也止境存眷两边在改日的和谐与竞争关系。
当被问及与和谐伙伴SambaNova的定位区别时,英特尔方面明确示意,SambaNova的大机架级架构更侧重于对延长颠倒敏锐、高并发的大畛域连合推理;而Crescent Island则聚焦于极高性价比,止境顺应企业端8-16卡畛域的一体机部署,二者酿成互补。同期,因其原生撑抓FP64,部分公司已对其HPC加快应用推崇出酷好,干系使命正在鼓舞中。
小结:
在2026年智能体需求大爆发的这个时期点,至强6+的发布明晰地展现了英特尔的计策念念路:遵守并放大其x86生态的深厚积淀,哄骗Intel 18A带来的制程红利,以极致的密度和能效去延续数据中心中一经巨大且不断增长的传统与新兴使命负载。
Kechichian在追溯时强调,英特尔的数据中心机策中枢在于在通盘使命负载之间蔓延,“咱们极力于于提供最顺应客户需求的家具,为下一阶段的AI基础设施提供撑抓。”
据悉,至强6+处理器与代号为Diamond Rapids的下一代P-core家具,将共同组成英特尔基于Intel 18A制程节点的数据中心CPU家具组合,而代号为Crescent Island的AI GPU则将代替此前英特尔基于AISC门路的Gaudi系列AI加快器IM体育(InPlay Matrix),以补足英特尔在数据中心AI加快器方面的过失。