IM体育官方网站 黄仁勋突袭英特尔AMD腹地, 联手王兴兴, 打平三大国产模子


作家 | ZeR0
英伟达憋了许久的芯片大招,终于来了。
智东西6月1日报说念,本日,在GTC台北大会上,英伟达创举东说念主兼CEO黄仁勋衣着闪亮的玄色皮衣发表主题演讲,发布2款芯片、1款桌面级AI超算、多款开源AI模子、框架、函数库,还与宇树科技聚会发布了基于宇树H2 Plus机器东说念主的全新东说念主形机器东说念主参考设想。

传奇已久的英伟达首款Arm架构PC芯片终于亮相,名为RTX Spark超等芯片。黄仁勋晓示与微软推出全新PC家具线,并称“这是40年来PC家具线初次全面更动”,雷同的智能体处理模式还将延展到各式征战上。

他说,缱绻机的此次创新,要紧进程不亚于庸俗手机演变为智高手机,英伟达已为此制定家具道路图,每一代架构(Grace Blackwell、Vera Rubin、Rosa Feynman)齐将配备台式机、条记本和使命站。
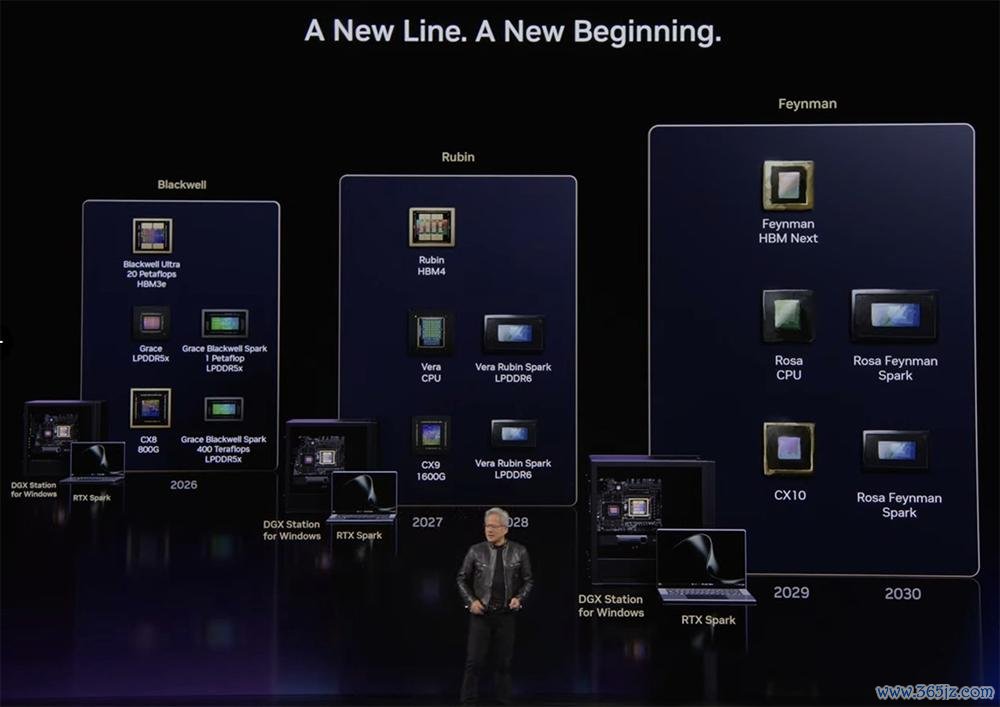
英伟达还发布了大众最刚毅的Windows平台桌面AI超等缱绻机DGX Station,以及英伟达豪赌2000亿好意思元市集的大招——专为智能体设想的Vera CPU。这恰是英伟达为智能体启动开拓的两大全新市集。

Anthropic、OpenAI、SpaceX三家AI巨头均率先部署Vera CPU。
在Q1财报期间,英伟达曾炫耀全新Vera CPU将开启一个价值2000亿好意思元的市集,展望Vera芯片收入将在本财年末达到200亿好意思元,成为“第二大销售孝顺者”。
本日,黄仁勋称Vera CPU具有创新性道理道理,其产能爬坡令他特殊适意,“目下的订单量已注定它将成为咱们公司历史上最快速、最胜利的家具发布。”
“NVIDIA Vera是英特尔和AMD x86_64处理器有史以来最刚毅的竞争敌手。”Phoronix CPU Benchmark Suite作家Michael Larabel评价说。

面向智能体部署,英伟达推出迄今最强模子Nemotron 3 Ultra、企业级智能体器具箱。其中,Nemotron 3 Ultra的智能体坐褥力测试分数跨越或打平了三个最初的国产智能体模子智谱GLM 5.1、月之暗面Kimi K2.6、阿里Qwen3.5。

面向物理AI,英伟达开源天下基础模子Cosmos 3、自动驾驶推理模子Alpamayo 2 Super,并晓示设立Cosmos定约。
面向AI工场,英伟达晓示Vera Rubin全面投产,并掏出了帮AI工场更踏实、节能的两大利器DSX OS和DSX MaxLPS。
黄仁勋也一如既往地晒了一下英伟达巨大的“一又友圈”,并不竭自如好奇好意思食的东说念主设,特殊感谢了在夜市的生果摊贩,还给了花娘小馆、富霸王猪脚餐厅等几家饭铺名字的特写镜头。

在演讲中,黄仁勋不竭飙新金句:
“实用AI时间仍是到来。”
“AI目下是利润生成器、GDP生成器。”
“缱绻即收入。”
“买得越多,赚得越多。”
“Token已成为盈利的收入单元。”
“只是因为芯片更低廉就聘用造作的架构,是没挑升念念道理的。”
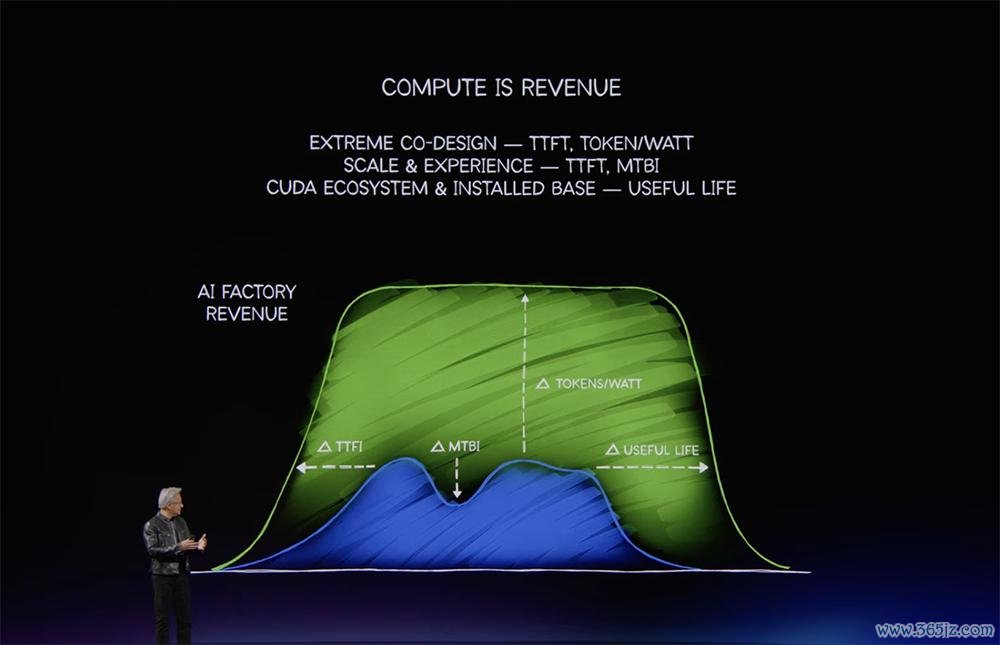
黄仁勋合计,在AI工场时间,每产生1个token就能盈利,每瓦性能、可靠性和系统寿命才是中枢财务杠杆。
AI工场每吉瓦本钱是200亿~300亿好意思元起步,现已攀升至500亿~600亿好意思元,不久后将达到800亿~1000亿好意思元。这些投资必须确保一次胜利。
在黄仁勋看来,AI会减少使命岗亭的说法“统统是天方夜谭”,AI反而鞭策了软件工程师需求的增长。
行为GTC常规,英伟达的机器东说念主生态全家福再次展出。

临了,在演讲末尾,英伟达播放了由一群东说念主形机器东说念主、OpenClaw龙虾、黄仁勋数字东说念主共同参演的音乐MV。

一、英伟达自研PC芯片登场:3nm制程,最高1P算力,能跑1200亿参数大模子
“时隔40年,微软与英伟达将从新发明PC(个东说念主缱绻机)。”黄仁勋晓示,英伟达与微软面向个东说念主智能体时间从新构想PC,推出为游戏和智能体而生的RTX Spark超等芯片。
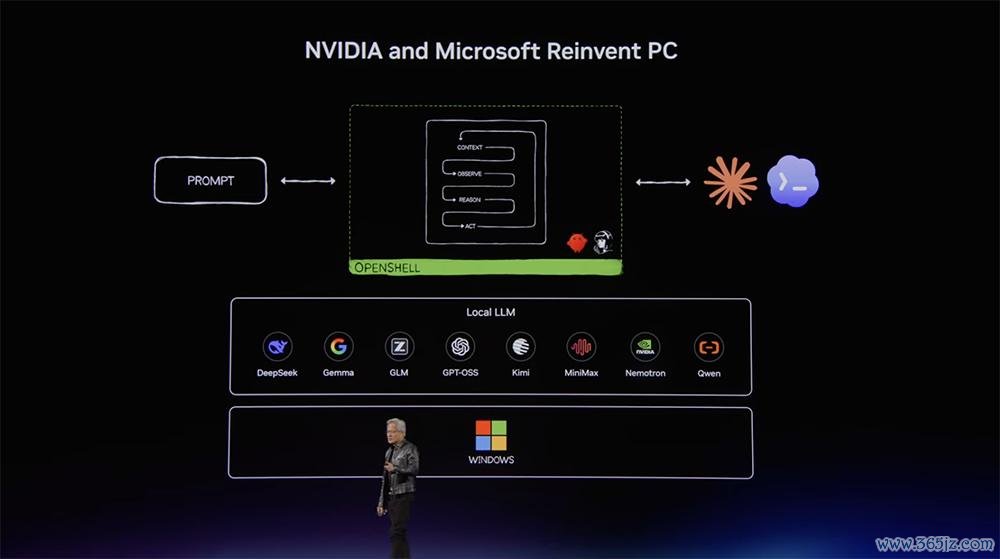
RTX Spark超等芯片领受台积电3nm工艺,内置700亿颗晶体管,提供128GB LPDDR5X调治内存和1PetaFLOPSFP4 AI算力,堪称是“史上能效最高的RTX芯片”。
其中,Blackwell RTX GPU有6144个CUDA中枢和第五代Tensor Core,并通过NVLink C2C芯片间互连时刻连结到与联发科合作开发的定制20核Grace CPU。

黄仁勋将RTX Spark称作“天下上制造过的最神奇的芯片”,“英伟达100%的软件栈齐在其上启动”。
RTX Spark和会了英伟达33年的创新末端,为大众首款专为个东说念主智能体打造的Windows PC提供能源。英伟达CUDA可在RTX Spark上原生启动。
搭载RTX Spark的PC,不错使用OptiX和DLSS渲染90GB超大型3D场景,使用英伟达Blackwell解码器剪辑12K 4:2:2视频,启动具有100万个token险阻文的1200亿参数大言语模子,以及使用光辉追踪、DLSS和Reflex以1440p分手率和每秒100帧以上的速率玩3A游戏。
畴前使用PC,用户要启动应用才调,点击鼠标,输入笔墨。目下使用RTX Spark和微软Windows,用户只需提议恳求,电脑就能完成使命。
此外,Adobe为RTX Spark从新设想了Adobe Photoshop和Premiere的架构,新版块在创意使命经由中,可将AI、剪辑、调色和殊效的处理速率最高普及至2倍。
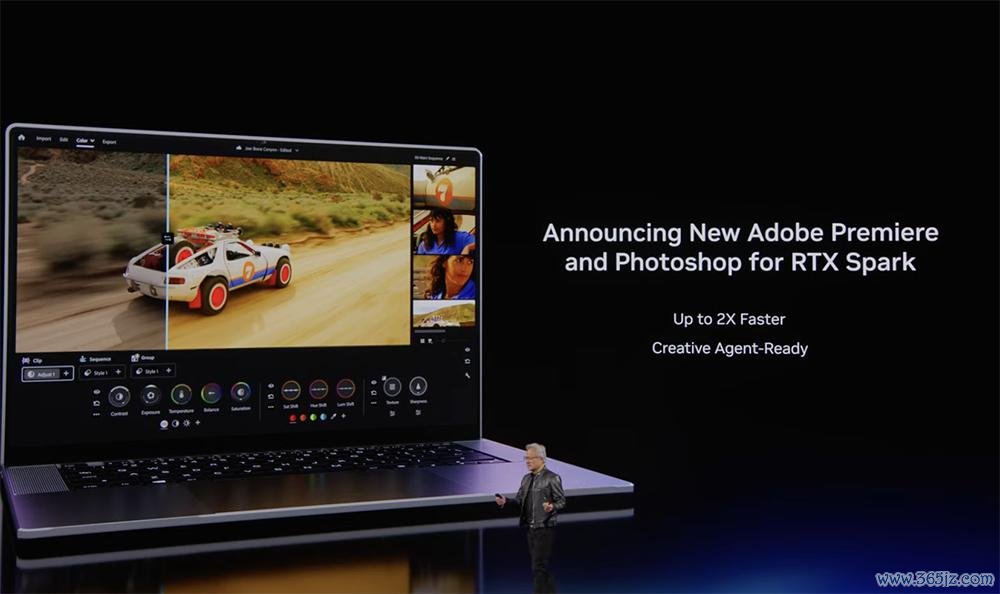
微软与英伟达正在对统共PC进行全面重塑,发布了面向智能体的全新三大Windows家具线,涵盖条记本电脑、台式机、桌面超算。
搭载RTX Spark的条记本电脑和紧凑型台式机将于本年秋季推出。
条记本电脑厚度仅为14mm,分量仅3磅,有14至16英寸多种尺寸聘用,不错24小时不辨认土产货“养龙虾”。

二、大众最强桌面级AI超算:748GB内存,20P算力,能跑万亿参数模子
英伟达本日还推出了一款适用于Windows的桌面AI超等缱绻机DGX Station。
DGX Station for Windows由微软合作开发,基于英伟达DGX Station系统设想,搭载英伟达GB300 Grace Blackwell Ultra桌面级超等芯片,提供最高748GB调治内存、20PetaFLOPSFP4算力、800GbpsConnectX-8 SuperNIC网络,与扫数Windows软件兼容,可启动万亿参数级AI模子,并可同期启动数百个智能体。

它复古额外竖立一张RTX Pro 6000使命站级GPU,将前沿AI算力与光辉追踪可视化相和会,用于跨创意设想和工程应用启动智能体。
DGX Station for Windows展望将于本年第四季度由主流系统集成商上市。
黄仁勋预言,翌日有一天,每个家庭齐会有一台AI超等缱绻机,启动着你扫数的智能体和助手。
三、Vera CPU:88核、1.2TB/s内存带宽,专为智能体设想
传统CPU追求每颗插槽的中枢数,切片、编造化、按小时出租。在智能体时间,CPU已成为GPU应用率的瓶颈,径直影响token迷糊量、时延与用户体验。
对此,英伟达推出其开端进的CPU——专为智能体而生的Vera CPU。

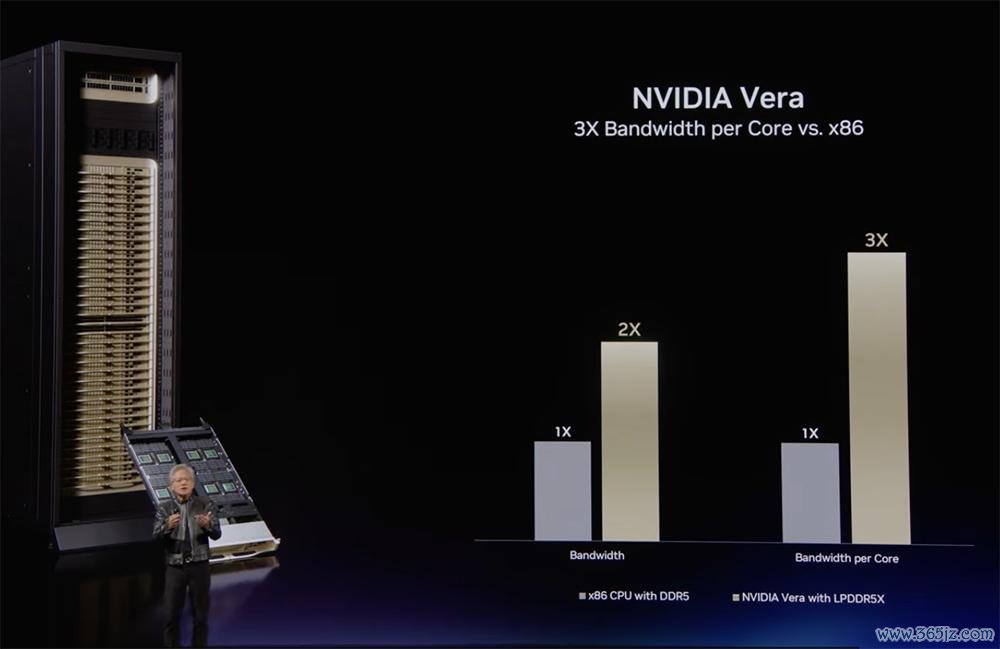
Vera CPU领受LPDDR5X内存(带宽1.2TB/s)、复古PCIe Gen6,表里带宽均达同类最高性能CPU的2至3倍,亦然首款在改革多位造作的同期不赔本带宽的CPU。
它基于英伟达第二代可推广一致性架构,将88个英伟达定制Arm中枢Olympus调治在一个单片Mesh网络上,在智能体使命负载上已毕了最高的单线程性能与最好能效比。
其中枢并未分散在多个Chiplet上,中枢之间的通讯速率比传统CPU快50%。Vera复古内存一致性,NVLink-C2C芯片间互联可将GPU直连到架构,还不错将Vera推广到多个插槽,在CPU之间已毕巨大频宽。
与Grace CPU比拟,Vera的每个中枢每时钟周期可多施行50%的辅导。
与配备DDR5的x86 CPU比拟,Vera每个中枢的带宽多达3倍;与x86 CPU比拟,峰值内存延长驳斥了40%,在检索分析与沙箱施行中保抓中枢供给实时。
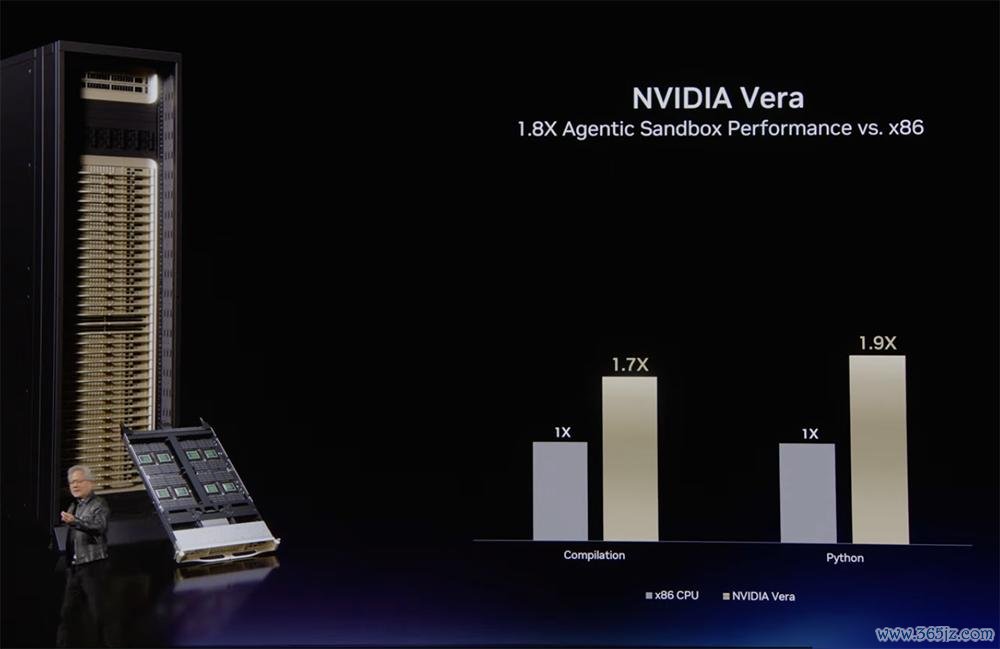
在Python代码分析、代码编译等常见智能体器具的行业范例基准测试中,Vera的智能体沙箱性能是与x86 CPU竞品质能的1.8倍。
该处理器有四大中枢设想原则:最初的每时钟辅导数(IPC)/ 单线程性能、每中枢带宽、总带宽以及能效。
Vera每时钟可取指、解码并施行10条辅导,IPC大众最高。
英伟达Olympus中枢专为当代数据中心使命负载、分支密集型Python启动时、器具调用和沙箱代码施行而优化。
每颗中枢均为迷糊量调优:神经分支预测器可在每个周期评估两个采取分支,10-Wide解码引擎可在每个周期代入更多使命负载,大型乱序施行引擎保管着辅导的运作,新式图引擎的高阶预取器可预测下一个数据旅途。

Vera片上高速互联总线带宽达3.4TB/s,无芯粒税(chiplet tax),无跨片范畴损耗,扫数中枢可与其他任何中枢及缓存无延长通讯,不存在调整打破。
Vera CPU已进入全面量产,并将于本年秋季通过系统合作伙伴认真上市。
Anthropic、OpenAI、SpaceX均是Vera CPU的早期领受者。

在SQL 1TB基准测试中,Vera CPU的SQL启动速率达到竞品的3倍。

Vera CPU正在为纽约证券来回所(NYSE)启动实时流处理,已毕了6倍的性能普及。
四、东说念主形机器东说念主参考设想:宇树机身+Sharpa奢睿手,开箱即用
NVIDIA Isaac GR00T参考东说念主形机器东说念主是首款基于英伟达Jetson Thor和Isaac GR00T平台构建的灵通东说念主形机器东说念主参考设想。

这个参考设想集成了宇树H2 Plus东说念主形机器东说念主、Sharpa Wave五指奢睿手、英伟达Jetson Thor处理器以及Isaac GR00T软件和使命经由,并预装了英伟达GR00T 1.7东说念主形机器东说念主模子,开箱即用。
具体包括:
宇树H2东说念主形机器东说念主底盘:身高近6英尺,重150磅,IM体育官方网站全身有31个解放度,用于东说念主体范例测试。
双Sharpa Wave触觉五指奢睿手:可已毕22个解放度的奢睿操作,使机器东说念主在体魄和手部达到75个解放度。
多视角传感器:包括一个头戴式立体录像头(水平140度,垂直102度),用于近距离操作的腕部录像头,以及一个用于通达追踪的惯性测量单元。
全身甘休:手臂扭矩高达120N·m,腿部扭矩达360N·m,手臂额定灵验载荷为7公斤,峰值灵验载荷为15公斤,举升和伸展才调更强。
英伟达Jetson AGX Thor T5000板载缱绻:配备NVIDIA Blackwell GPU,FP4 AI性能达2070TFLOPS,14核Arm CPU,128GB调治内存,以及可竖立的40至130瓦功率范围,用于实时传感器处理和机器东说念主推理。
复古以太网、Wi-Fi 6、蓝牙5.2、USB连结,并配备一系列麦克风和扬声器,用于语音交互。
电板容量为15Ah,0.972kWh,续航时期约为3小时,可延长启动时期。
费事要紧罢手功能,可快速安全地脱离机器东说念主。
宇树科技已在官方公布Isaac GR00T参考东说念主形机器东说念主的全身竖立:

本年年底,NVIDIA Isaac GR00T参考东说念主形机器东说念主将由宇树科技提供。
NVIDIA Isaac GR00T开发者平台还将复古宇树G1东说念主形机器东说念主。针对宇树G1的参考使命经由展望很快将在GitHub和Hugging Face上提供给机器东说念主开发东说念主员。
为什么要作念这件事?
黄仁勋说,征询实验室从东说念主形机器东说念主制造商那边赢得的机器东说念主,尚未达到量产就绪现象,因此,实验室将大齐时期和元气心灵花在使机器东说念主的基本功能闲居运作上。
而一个粗略鸿沟化开发、配备备用零件、开箱即用的平台,将缱绻、软件栈、手部和机身全部集成在统共,调治设想协同启动,并配备齐备的仿真才调,使征询实验室能径直开箱使用,立即参加征询。
四、开源英伟达最强天下模子:5500亿参数,5倍速率、本钱驳斥30%
英伟达努力于为全天下构建开源模子,让东说念主东说念主齐能打造属于我方的智能体。
Nemotron 3 Ultra是英伟达迄今最强的新一代开源基础模子,亦然面向自主智能体才调最强的模子,共有5500亿个参数。
这是大众首个基于SSM(现象空间模子)与众人混杂(MoE)混杂架构的模子。
它的速率是同级别最初模子的5倍,完成换取智能体任务所需的启动本钱驳斥30%。

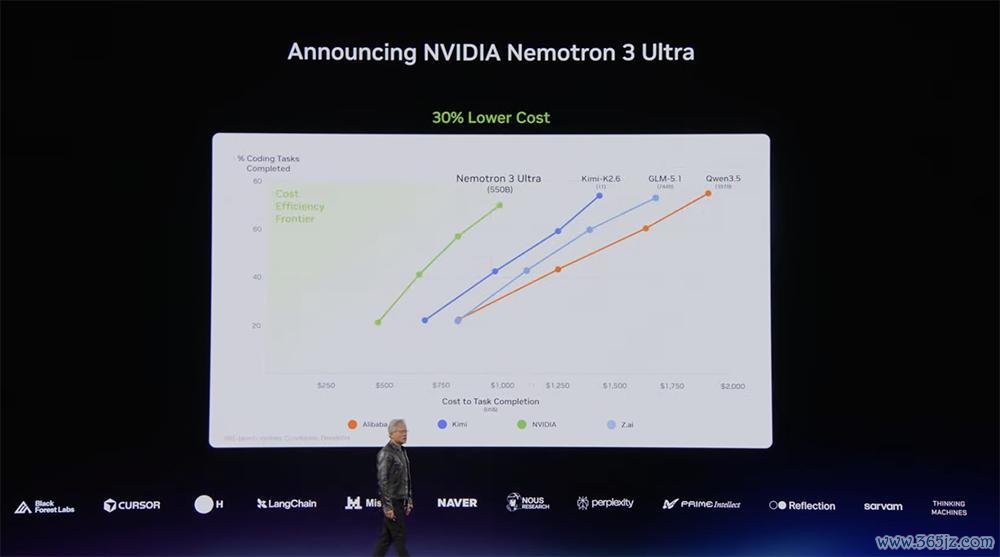
“岂论是总浮点运算量如故总推理时期,均优于目下最具性价比的开源模子。”黄仁勋总结说。
目下英伟达正在研发Nemotron 4。
五、打造智能体器具包,智能体将芯片设想考证提速40多倍
黄仁勋说,底下这张图是本场演讲中最要紧的一张幻灯片,亦然最中枢的论断:
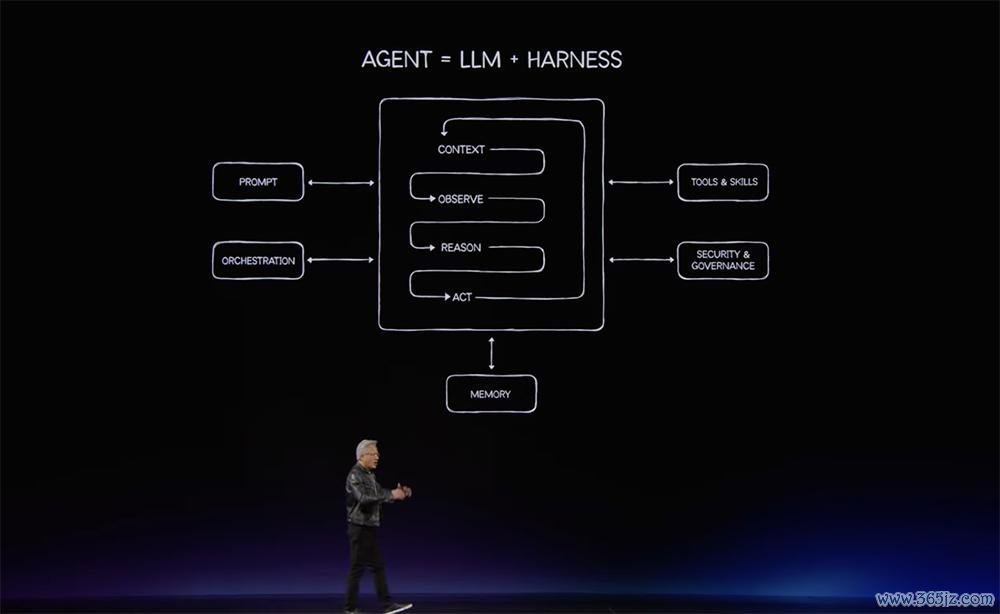
这是翌日十年的应用模式、缱绻模式,每家公司齐会领受。
何如匡助企业安全地构建和启动智能体?为此,英伟达推出了企业级智能体器具包(NVIDIA Agent Toolkit for Enterprise AI)。
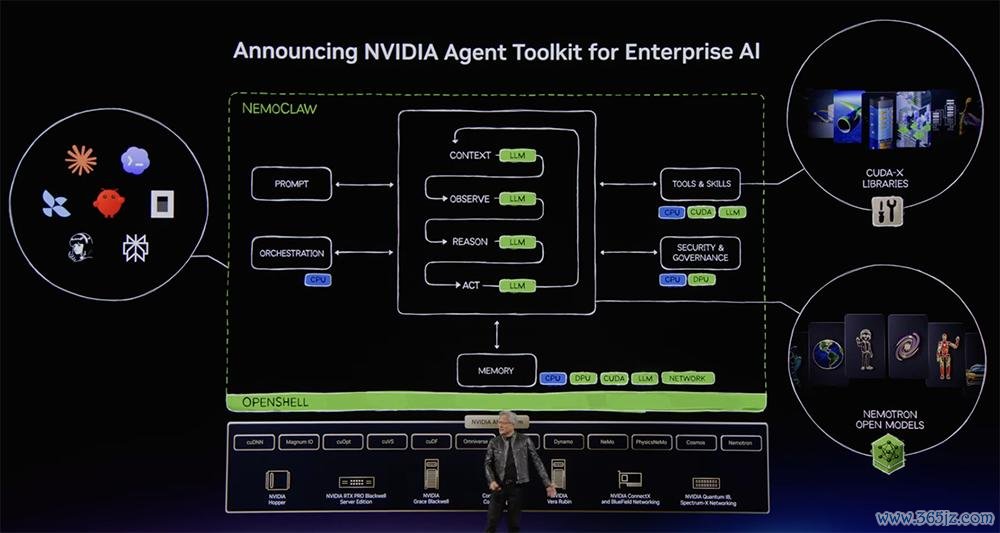
英伟达智能体器具包取悦了大言语模子、智能体框架和企业级启动时,能为企业里面提供高度安全的环境。
扫数智能体齐不错使用基于NVIDIA CUDA-X库(包括 cuDF、cuOpt、AI-Q、NeMo、PhysicsNeMo和CUDA-Q)的智能体Skills。
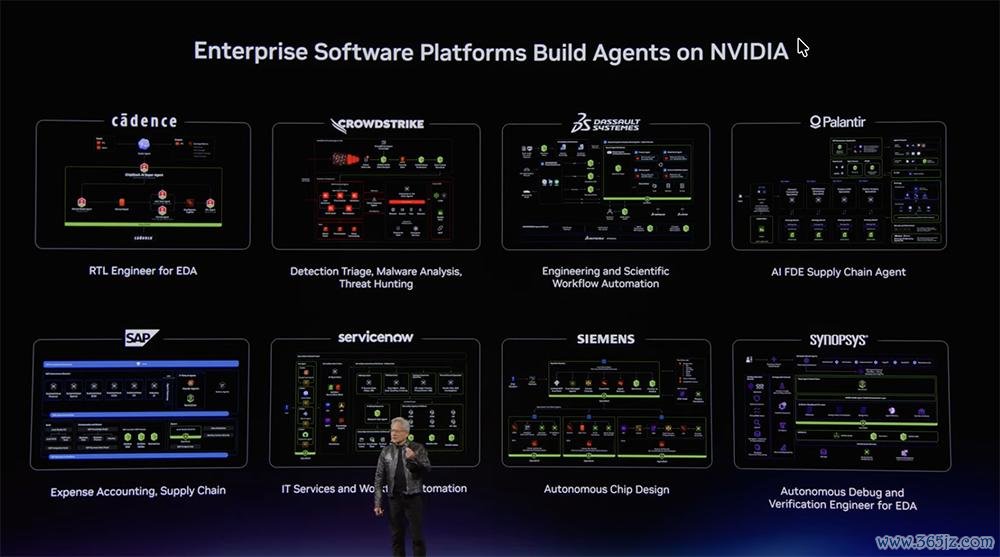
这些经过考证的英伟达智能体Skills可在Claude Code插件市集和Hermes Skills Hub中找到。
NVIDIA OpenShell是这些自主智能体的安全启动时环境,为智能体操作提供独处的沙箱、聚积式战略施行和贬责照看网关,并可在Ubuntu、Windows、Red Hat OpenShift等主流企业平台上启动。
黄仁勋说,他最可爱的智能体应用案例之一是芯片设想。
英伟达与Cadence合作,打造了一款芯片设想超等智能体。
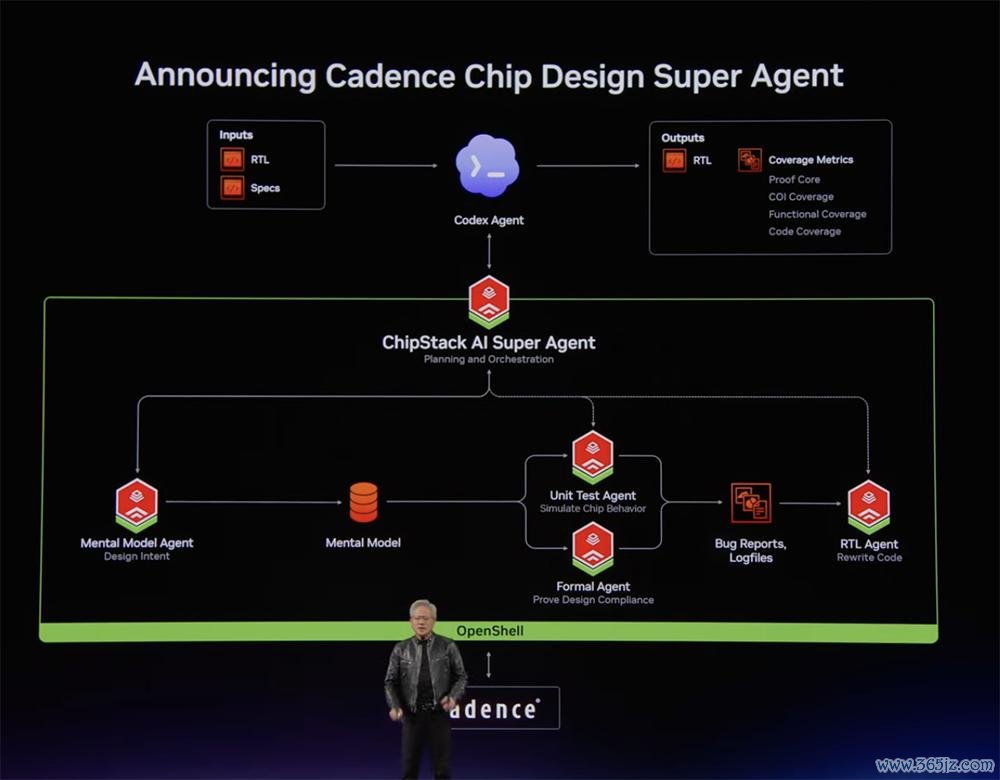
通过和谐寄存器传输级生成、测试平台创建、总结测试和调试,这个超等智能体可自动启动数百次模拟和神色化稽察,可将正本耗时数周的使命压缩到几小时,考证周期快了40多倍。
“英伟达领非凡千名芯片设想师。咱们将引入数十万名Cadence超等智能体与咱们协同使命,加快公司发展。”黄仁勋说。
六、物理AI:全新天下模子、自动驾驶推理模子开源
物理AI最大的挑战是数据。对此,英伟达推出一款面向物理AI的开源天下基础模子Cosmos 3。
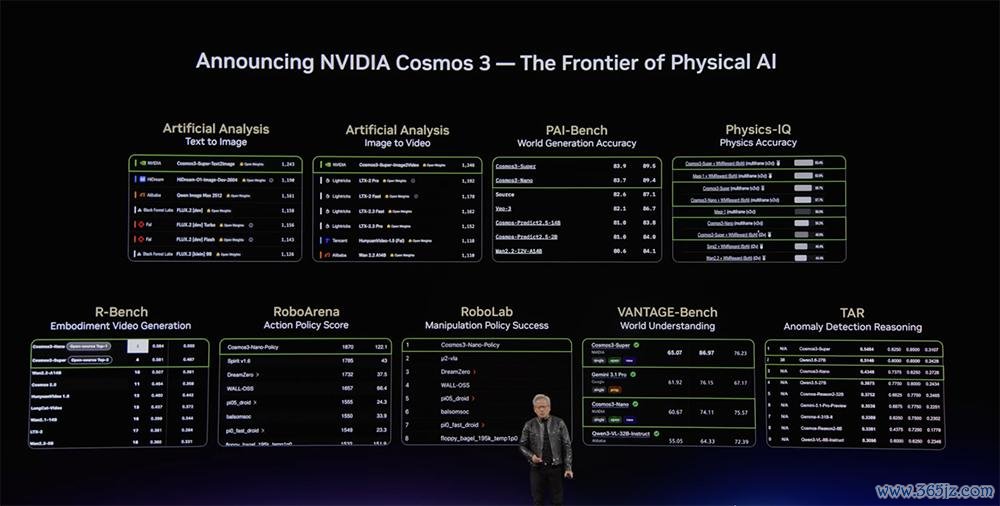
Cosmos 3基于混杂Transformer架构,将视觉推理和跨文本、视频、图像、环境音效和动作的多模态生胜利能整合到一个模子中,匡助开发者创建具有物理险阻文的天下数据。
该模子是VANTAGE-Bench测试榜上名治安一的灵通视觉言语模子。
开发者可针对不同情势和应用场景对Cosmos 3进行后稽察(post-train),比如用于天下推理、合成数据、闭环仿真器或天下动作模子。
扫数模子、代码和稽察有经营均已在Hugging Face和GitHub上灵通。
同期,英伟达晓示设立Cosmos定约(Cosmos Coalition),Agile Robots、Black Forest Labs、Runway、LightTricks、Skilled AI等部分顶尖AI实验室正与英伟达共同开发下一代Cosmos。

面向自动驾驶领域,英伟达也推出了全新物理AI模子、框架、函数库:
(1)Alpamayo 2 Super:一款领有320亿参数的灵通自动驾驶推理模子,专为推理、缱绻、标注和评估设想。
(2)AlpaGym:一款开源闭环强化学习框架,让路发者粗略在仿真环境中稽察自动驾驶战略,模子动作粗略信得过影响后续仿真末端。
(3)OmniDreams:一款基于Cosmos构建的专用脚色模子,可大鸿沟生成防卫、传神的长尾驾驶场景。
(4)全新Omniverse NeRF函数库:能在单块GPU上以25ms以内的速率完成信得过天下的重建与渲染,使开发者可实时评估模子的感知效果。
这些发布共同为自动驾驶开发者提供了一条更快速、更安全的L4自动驾驶已毕旅途。
七、Vera Rubin已全面投产
本年事首发布的Vera Rubin,现已全面投产。

黄仁勋说,Vera Rubin是英伟达史上最具宏愿的名目,全公司40000名工程师齐参与其中。
Vera Rubin专为启动智能体而生,是一套齐备的剖判式漫衍式智能体处理系统,包含Vera Rubin NVL72系统、液冷Vera CPU机架、Vera BlueField-4 STX存储和安全系统、Groq 3 LPX低延长推理托架和Spectrum-X Ethernet Photonics网络。
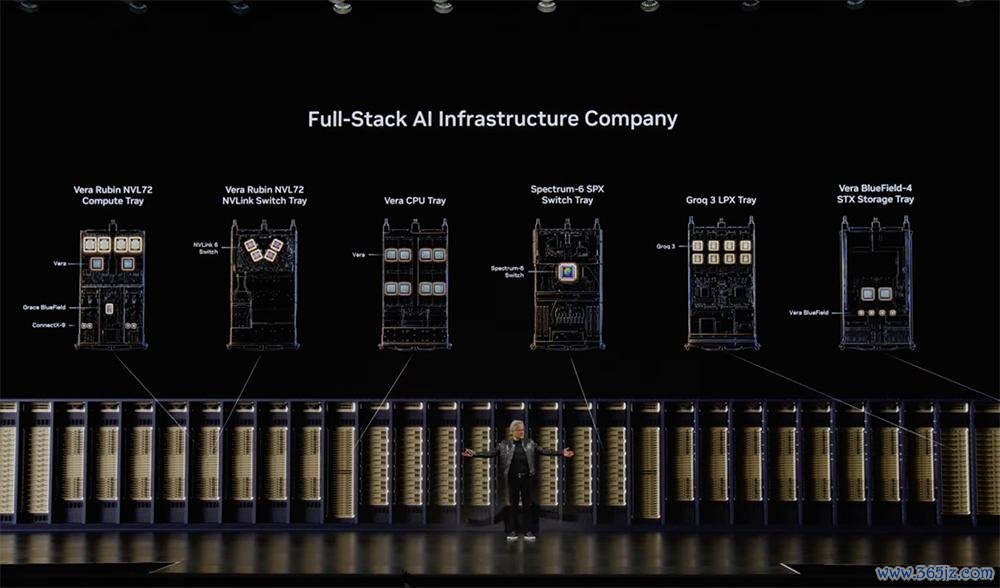
该平台由中国台湾跨越150家供应链生态合作伙伴参与,遍布数百个工场。扫数组件均通过极致协同设想(extreme co-design)打造。
英伟达为Vera Rubin打造的供应链,鸿沟是Grace Blackwell的2倍。
畴前拼装一个 Grace Blackwell机架需要2小时,目下只需5分钟。产能更高,出货速率也大幅普及。
单个液冷Vera CPU机架容纳256颗CPU,负责模子编排、内存调整与器具调用。

在富士康与广达,Groq LPX逐渐成形。256颗Groq LPU漫衍于16个托盘,片上静态就地存储器(SRAM)带宽高达40PB/s,已毕超低时延。
Spectrum-X Ethernet Photonics是大众首款领受共封装光器件的200Gb/s SerDes以太网交换机,现已参加坐褥。
Vera BlueField-4 STX由BlueField-4加快,在芯片层面处理安全问题:DOCA Argus可将威逼检测时期从分钟裁汰至毫秒;DOCA Vault可在机架鸿沟上保护AI数据。
八、DSX:帮企业构建和照看AI工场,换取功耗下多塞40%的GPU
英伟达也曾在缱绻机里面设想一颗芯片,然后在缱绻机里面仿真一个系统,如今终于不错在数字框架、数字仿真器、数字天下中构建这些巨大的系统,在破土动工、参加真金白银之前考证一切。
黄仁勋解说说,RTX对应GPU,DGX对应系统,而DSX对应基础步骤。
天下正在竞相建设AI工场芯片、机架、网络、电力、冷却、电网每一层齐必须重新到尾协同设想,因为“缱绻即收入”。
NVIDIA DSX所以最高效劳和盈利才调设想、建设与运营AI工场的参考设想,努力于已毕最低Token本钱,并看管能源电网安全。
本日,英伟达推出适用于DSX平台的全新AI工场操作系统DSX OS和DSX MaxLPS。
DSX OS是一款模块化、开源、可推广的基础步骤软件,专为AI工场运营商设想,负责竖立、运营、监控和建造基础步骤,将已装配的系统转换为简直赖的多田户、高弹性、AI就绪的算力容量。
DSX OS开源组件的生态合作伙伴可接入自有软件,并通过ISV(独处软件供应商)生态加以推广。

DSX MaxLPS是一套专门设想的时刻组合,能与Vera Rubin硬件的动态功耗特质协同配合,统筹优化算力迷糊,匡助数据中心运营商在换取功耗、电力预算下可多提供40%的GPU,每年可新增数十亿好意思元的营收。
热液冷却时刻在45℃下启动,耗水更少、能耗更低,将更多电力导向创收算力;动态电力调配时刻将电力从机架到机架纯真调整,回收闲置功耗,将其运输至有使命负载的场所;机架内削峰平滑时刻阻扰电流尖峰和功率浪涌,踏实统共工场的供电;智能体团队与DSX MaxLPS和谐,抓续和谐冷却与电力,以怡悦使命负载需求。
星空体育中国官网入口结语:一切为了帮客户已毕最高利润
2026年正成为AI发展史上极为要紧的一年。智能体的拐点正在鞭策坐褥力大幅普及,创造巨大的交易机遇。
黄仁勋总结了英伟达构建AI基础步骤的上风:
1、首个Token时延、初次推理启动时延、稽察启动时延齐更短。
2、每瓦迷糊量、每瓦Token数是天下顶级。只是因为芯片更低廉就聘用造作的架构,这不合算。每瓦Token数才是关键,买得越多,赚得越多。
3、可靠性。英伟达仍是在超大鸿沟下运营很久,这些教悔特殊贵重。
4、系统使用寿命。每隔几个月,软件行业就会流露出新时刻。英伟达的系统遍布大众,软件开发者从英伟达CUDA起步,因此生态系统和钞票的灵验使用寿命当然会更长。要是钞票寿命长,则总领有本钱(TCO)低。
正如黄仁勋强调的IM体育官方网站,英伟达仍是不单是是一家GPU公司和系统公司,而是一家基础步骤公司,一切齐是为了帮客户已毕最大营收、最高利润,并尽快已毕经营。